B树原理与实现
前言
B树是为磁盘等慢速IO设备设计的一种平衡搜索树,B树类似于红黑树,但它在降低I/O操作数方面要更好一些,许多数据库使用 B树或B树的变种来存储信息。
B 树与红黑树的不同之处在于 B树的节点可以有很多孩子,从数个到数千个。含有 n 个节点的B树的高度为 O(ln n),一棵B树的严格高度可能比一棵红黑树的高度要小许多,因为它的分支因子,即表示高度的对数的底数可以非常大。因此我们可以使用 B树在 O(lg n) 内完成一些动态集合操作。
磁盘结构
一个磁盘的典型结构如下:

磁盘是一种辅存,一个计算机系统的主存使用硅存储芯片组成,这种存储技术每位的存储代价一般比磁存储技术高不只一个数量级。虽然固态硬盘正在越来越普及,但是磁盘具有的容量大,价格实惠等特点,还依然被广泛使用。一个典型的磁盘由以下部分组成,盘片,磁道,读/写头,主轴和磁臂组成。一个盘片由多个磁道组成,形状上看类似于同心圆。一个磁道由多个扇区组成,扇区是磁盘的最小读写单位,即每次可以读写一个或多个扇区。大多数磁盘的扇区大小为 512字节,即每次读取或写入 512字节。
那么磁盘如何读取数据?主轴带动盘片旋转,这样 读/写磁头 就能按位读/写扇区的数据。旋转磁臂就可以切换到不同的磁道,这个过程叫做寻道。磁盘之所以慢就是因为它在读/写数据的时候涉及到机械运动,分别是盘片旋转和磁臂移动。一个盘片旋转一周的时间要比硅存储的常见存取时间高出 5 个数量级。为了摊还机械运动所花费的等待时间,磁盘会一次存取多个数据线而不是一个。信息被分为一系列相等大小的在柱面内连续出现的页面(page),一页的长度可能为 211到214。
B树介绍
一个典型的 B树应用所要处理的数据量非常大,以至于所有数据无法一次性装入主存。B树算法所需读或写的页数无法一次装入内存,B树算法将所需的页面从磁盘复制到主存,然后将修改过的页面写会磁盘。主存的大小并不限制被处理的 B树的大小。
大多数系统中,一个B树算法的运行时间主要由它所执行的 disk-read() 和 dis-write() 操作的次数决定,我们希望这些操作能读或写尽可能多的信息,一个B树节点通常和一个完整磁盘页一样大,并且比盘页的大小限制了一个 B树节点可以含有的孩子的个数。
对存储在磁盘的一棵大的B树,通常看到分支因子在 50到 2000之间,具体取决于一个关键字相对于一页的大小。一个大的分支因子可以大大地降低树的高度以及查找任何一个关键字所需的存取次数。下图所示一棵分支因子为 1001,高度为 2 的B树,它可以存储超过 10 亿个(1001*1001-1)*1000关键字。由于根节点可以持久地保存在主存中,这棵树中查找某个关键字至多只需两次磁盘存取。

B树的每个节点一般在磁盘中分配空间,以下为了简化分析,在内存中分配节点,这样就可以省略在磁盘中分配节点的过程,以及必要的读写磁盘操作:disk-read() 和 dis-write() 过程。
B树的定义
一棵B树具有以下性质:
-
(1)B树的每个节点 x 都具有以下属性:
-
x.n 存储在节点 x 中的关键字个数。
-
x.n 个关键字本身 x.key0, x.key1,…, x.keyn-1,以升序排列,注编程语言数组下标从 0 开始。
-
x.leaf 布尔值,表示节点 x 是否是叶节点。
(2)B树的每个内部节点具有以下属性:
- 包含 x.n+1 个指向其孩子的指针 x.c0,x.c1,…,x.cn,叶节点没有孩子节点,它们的 ci 属性值未定义。
(3)关键字 x.keyi对子树节点中的关键字进行分割,如果 ki为任意一个存储在以 x.ci为根的子树中的关键字,那么:k1<=x.key1<=k2<=…<=x.keyn<=kx.n+1,如下图所示:
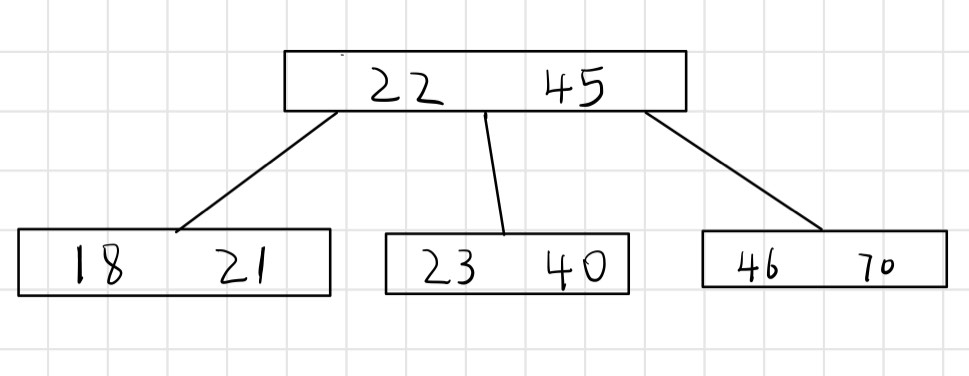
(4)每个叶节点具有相同的深度,即树的高度 h
(5)每个节点所包含的关键字个数有上界和下界,用一个被称为B树的最小度数的固定整数 t>=2 来表示这些界:
-
下界:除了根节点以外的每个节点必须至少有 t-1 个关键字。除了根节点和叶子节点以外的每个节点至少有 t 个孩子。如果树非空,根节点至少有 1 个关键字。
-
上界:每个节点至多可包含 2t-1 个关键字,一个内部节点(非叶子节点)至多可有 2t 个孩子。当一个节点有 2t-1 个关键字时,称该节点为满的。
-
t 值越大,B树的高度就越小。
-
t == 2 时的B树是最简单的。每个内部节点有2个,3个或则4个孩子,即一棵 2-3-4 树。实际上,t的值越大,B树的高度越小。
B树的高度
如果 n>=1,那么对任意一棵包含 n 个关键字,高度为h,最小度数 t >= 2 的B树T,有 h<= $\log_t{(n+1)/2}$
在一棵树中检查任意一个节点都需要一次磁盘访问,所以B树避免了大量的磁盘访问。
节点定义
1 | struct TreeNode |
B树上的基本操作
搜索B树
1 | pair<TreeNode *, int> |
时间复杂度
它的搜索过程遇到的节点构成了一条从树根向下的简单路径。B树需要访问的节点个数为 O(h) = O($\log_t{n}$),h 为 B树的高度,n 为B树所含关键字的个数。由于 x.n <= 2t,while 循环在每个节点所花费的时间为 O(t),总的 cpu 时间为 O(th) = O(t$\log_t{n}$)。
创建一棵空的B树
使用构造函数创建B树
1 | Btree::Btree(int _t,bool _leaf){ |
插入B树
我们将关键字插入一个已经存在的叶节点上,由于不能插入一个满的叶节点,需要引入一个操作,将一个满的节点y(2t-1个关键字)按其中间关键字 y.keyt分裂为两个各含 t-1 个关键字的节点。中间关键字被提升到y的父节点,以标识两棵树的划分点。如果 y 的父节点也是满的,就必须在插入新的关键字之前将其分裂,最终满节点的分裂会沿着树向上传播。
插入
判断根节点是否满,如果非满则调用insertNonfull,如果满了则需要调用splitChild将根节点分裂为两个,创建新的根节点
1 | void |
分裂B树中的节点
1 | void Btree::splitChild(TreeNode *x,int index) |
插入非满节点
1 | void |

时间复杂度
insert 访问O(h) 个节点,h 为 B树的高度,每次调用 insertNonfull,所需时间为 O(1),insertNonfull为递归,递归深度最多为 O(h),每次递归对 n 个关键字进行扫描,由于 x.n <= 2t,每个节点所花费的时间为 O(t)。总的 cpu 时间为 O(th) = O(t$\log_t{n}$),n 为B树所含关键字的个数。
删除
参考:https://www.geeksforgeeks.org/delete-operation-in-b-tree/
参考
《算法导论》